Claude Code 实战沉淀:从 Agent 到 Skill 的全景指南
写在前面
Claude Code(下面简称 CC)是 Anthropic 官方的 AI 编程 CLI。和很多人想的不一样,它不是「ChatGPT 的命令行版」——而是一个开箱即用、带工具调用、能跑 SubAgent、能装插件、能挂 MCP 的完整 Agent 系统。
本文是我这段时间用下来的沉淀,把核心架构拆成七层讲清楚,每一层配上能直接落地的配置和踩坑。
一、Claude Code 的能力分层
先看一张「七层蛋糕」,对照看后面每个章节会更清楚:
| 层级 | 组件 | 作用 |
|---|---|---|
| 基座模型 | Opus / Sonnet / Haiku | 推理、理解、生成 |
| Agent 框架 | 主 Agent + SubAgents | 任务编排与并行执行 |
| 工具层 | Read / Edit / Bash / Grep … | 与文件系统、终端交互 |
| 扩展层 | MCP Servers | 接入数据库、API、飞书等外部服务 |
| 配置层 | CLAUDE.md / settings.json | 项目级指令与行为定制 |
| 技能层 | Skills | 封装可复用的领域知识与工作流 |
| 自动化层 | Hooks | 事件驱动的全流程自动化 |
七层并不是孤立的——一个真实工作流通常是:CLAUDE.md 定语境 → 触发某个 Skill → Skill 编排 SubAgent 并行 → SubAgent 调用 MCP 工具 → Hooks 在关键节点自动收尾。
二、SubAgent:被低估的并行红利
「CC 的 Agent」到底指什么
第一次看官方设置面板里 “Agents” 这一项时容易困惑:CC 本身不就是 Agent 吗?为什么还要再创建一个?
答案是——CC 自身确实是个完整的 Agent,但 UI 里的 “Agents” 指的是 SubAgent:在主对话窗口之外、拥有独立上下文的轻量工作单元。
为什么要用 SubAgent
| 维度 | 串行(无 SubAgent) | 并行(有 SubAgent) |
|---|---|---|
| 执行方式 | 拿信息1 → 拿信息2 → 拿信息3 → 汇总 | 同时拿 1/2/3 → 汇总 |
| 上下文消耗 | 所有中间结果堆在主窗口 | 子窗口独立处理,只回传结果 |
| 数据隔离 | 中间噪声容易污染主线 | 主子隔离,结果干净 |
| 协作模式 | 单人作业 | 主窗口像 Team Leader 派活 |
我们组实测下来:相比传统串行,使用 SubAgent 并行编排后,任务时长下降约 40%,文档产出质量提升约 30%。原因不只是「快」,更关键的是主窗口上下文没被中间垃圾吃掉。
两种使用方式
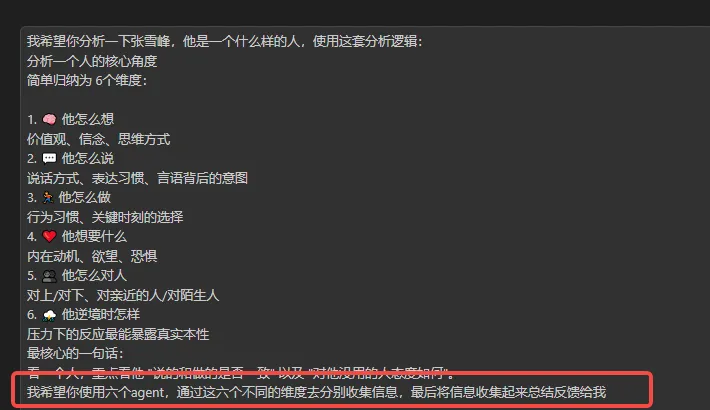
**方式一:在 Skill / Prompt 里声明多 Agent 协作。**适合一次性的并行调研。例如「用 6 个 Agent 分别从 6 个维度分析一个人,最后汇总」:
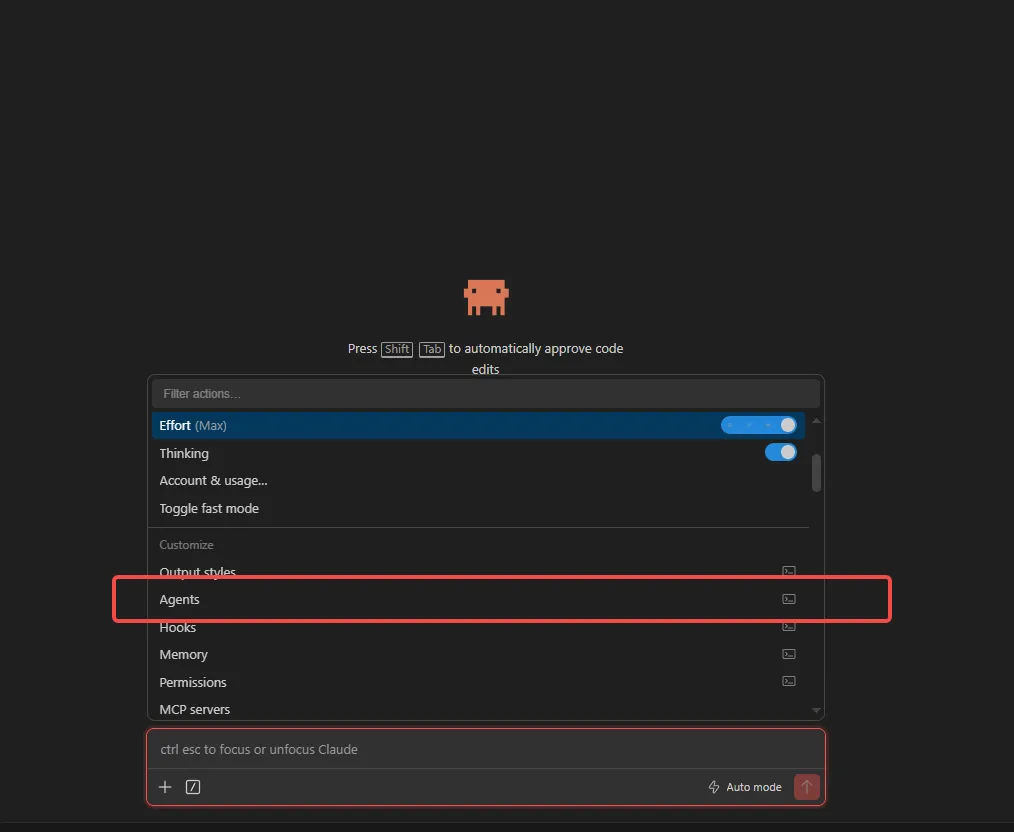
**方式二:通过设置面板里的 Agents 入口手动创建。**这种是「专职成员」——独立模型、独立工具集、独立记忆,可以跨任务复用:
两者的取舍:
| 维度 | 声明式(在 Skill 里) | 自定义 Agent |
|---|---|---|
| 生命周期 | 任务结束自动销毁 | 持续存在,跨任务复用 |
| Skill 调用 | 受限于主 Agent | 可独立挂 Skill |
| 记忆 | 无 | 独立 Memory |
| 模型 | 跟随主 Agent | 可单独指定 |
| 适合场景 | 一次性批量信息收集 | 持续交互、独立上下文 |
三、Skill:把工作流封装成函数库
心智模型
Skill 是 CC 里可复用的提示词包。最贴切的类比是「函数库」:
- Skill = 函数:封装能力,有明确触发条件和产出
- Skill 参数 = 函数入参:调用时传上下文
- Skill 组合 = 调用链:多个 Skill 串起来组成复杂工作流
Skill 文件长什么样
一个 Skill 本质就是一个 SKILL.md——YAML frontmatter 描述元数据,Markdown 正文是给 CC 看的指令书。
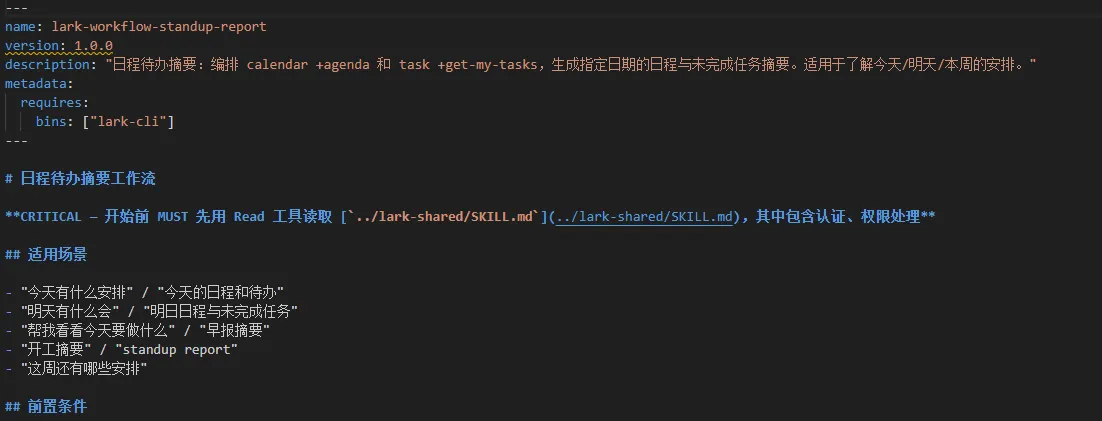
核心字段就四个:
| 要素 | 说明 |
|---|---|
name | 技能名称,用于调用 |
description | 触发条件,CC 据此判断何时自动唤起 |
| 指令内容 | 操作步骤、规则、约束、注意事项 |
| 引用关系 | 依赖的其它 Skill 或参考文档 |
写 Skill 最值得花时间打磨的就是 description——这是 CC 自动调度的唯一依据。写得越具体、越带触发词,命中率越高。
四、MCP:AI 世界的 USB 接口
解决了什么
MCP(Model Context Protocol)是 Anthropic 推出的开放协议,让 AI 模型可以用统一格式接入外部工具和数据源。
| 传统方式 | MCP 方式 |
|---|---|
| 每个工具单写一套 Prompt 适配 | 统一协议,一次接入 |
| 工具调用格式各异 | 标准化输入输出 |
| 难以组合多个工具 | 工具自动发现与编排 |
| 数据安全靠口头约定 | 协议级权限控制 |
一个完整配置示例
在 settings.json 里挂三个常用 Server:
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "ghp_xxxxxxxxxxxx"
}
},
"postgres": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-postgres", "postgresql://user:pass@localhost/mydb"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/project"]
}
}
}三个字段的含义:
command:启动 MCP Server 的命令args:传给命令的参数(Server 包名 + 连接信息)env:环境变量,存 Token、密钥这类敏感信息
配置文件按生效范围放在两处之一:
- 项目级:
.claude/settings.json - 用户级:
~/.claude/settings.json
常见 MCP Server 速查
| Server | 功能 | 典型场景 |
|---|---|---|
| filesystem | 文件系统访问 | 读写项目文件 |
| github | GitHub API | PR/Issue 管理 |
| postgres / mysql | 数据库 | 查询、迁移、Schema 分析 |
| lark-cli | 飞书全家桶 | 文档、消息、日历、审批 |
| browser | 浏览器控制 | UI 测试、网页抓取 |
MCP 和 Skill 的关系
很多人会问这俩是不是重复。实际上是互补的:
- MCP 提供「工具能力」——CC 能做什么
- Skill 提供「领域知识」——CC 知道怎么做
完整流程基本是 Skill 编排流程 → 调用 MCP 提供的工具 → 产出结果。
五、CLAUDE.md:项目级的「行为规范」
作用
CLAUDE.md 是放在项目根目录的指令文件,类似 .editorconfig 或 .eslintrc——定义 CC 在当前项目里的行为规范。每次启动对话都会自动读取,所以适合放团队约定、技术栈说明、禁忌操作这类信息。
可以配什么
| 类型 | 示例 | 效果 |
|---|---|---|
| 代码规范 | 使用 TypeScript 严格模式 | CC 生成的代码自动遵循 |
| 项目架构 | src/components/ 放 UI 组件 | 创建文件时放对位置 |
| 测试要求 | 每个新功能必须配单测 | 自动补测试文件 |
| 提交规范 | 用 Conventional Commits | /commit 自动遵循 |
| 禁止操作 | 不许用 any、不许 console.log | 主动规避 |
| 上下文信息 | React 18 + Zustand | 生成代码匹配栈 |
三层优先级
.claude/CLAUDE.md ← 子模块级(最高)
CLAUDE.md ← 项目级(最常用)
~/.claude/CLAUDE.md ← 个人全局合并时高优先级覆盖低优先级。
写作建议
| ✅ 推荐 | ❌ 避免 |
|---|---|
| 具体优于抽象:「用 dayjs,不用 moment」 | 「使用轻量库」 |
| 规则配上原因:「不直接调 API(便于 mock)」 | 干巴巴的禁止 |
| 用代码片段说明正确写法 | 纯文字描述 |
| 随项目演进定期维护 | 写完不管 |
六、输出风格、自定义 Agent、权限、插件
VS Code 命令面板里 CC 的设置菜单除了 MCP/Hooks/Memory,还有这四个高频项。
Output Styles
只改 CC 的说话风格,不改它的能力。内置三种:
| 风格 | 特点 |
|---|---|
| Default | 标准软件工程助手,简洁高效 |
| Explanatory | 边干边讲解,适合学习项目模式 |
| Learning | 协作式边学边做,CC 标 TODO(human) 让你亲手写关键部分 |
自定义风格写成 Markdown 放到 ~/.claude/output-styles/ 或 .claude/output-styles/ 即可。frontmatter 里 keep-coding-instructions: true 保留默认编码指令,false 则剥离(适合纯陪聊型角色)。
自定义 Agent
前面 SubAgent 章节提到的「方式二」就是这里。配置格式和 Skill 类似——YAML frontmatter + Markdown 正文。一个真实例子:
---
name: test-case-quality-scorer
description: 当用户需要评估、评分、审查测试用例质量时使用此 Agent。
model: opus
color: red
memory: project
---
You are a Test Case Quality Scorer Pro ...
(系统提示词正文)关键字段:
model:opus / sonnet / haiku,按任务复杂度选memory: project时 Agent 的独立记忆存到.claude/agent-memory/,可通过 Git 团队共享color:UI 上的视觉标识,多 Agent 时方便区分
权限管理
CC 把工具分三类做差异化审批:
| 类型 | 示例 | 默认行为 |
|---|---|---|
| 只读 | Read / Grep / Glob | 自动通过 |
| Bash 命令 | Shell 执行 | 需审批,“不再询问”永久生效 |
| 文件修改 | Edit / Write | 需审批,“不再询问”仅当前会话 |
六种模式按场景切换:default(日常)/ acceptEdits(信任文件操作)/ plan(只读分析)/ auto(后台审查)/ dontAsk(严格白名单)/ bypassPermissions(CI 全自动)。
精细规则写在 settings.json:
{
"permissions": {
"allow": ["Bash(npm run *)", "Bash(git commit *)", "Read"],
"deny": ["Bash(rm -rf *)", "Edit(.env)"]
}
}优先级:deny > ask > allow,deny 永远最高。
Plugin 插件
如果说 Skill 是「一个函数」,Plugin 就是「一个函数库」——一次性带来多个 Skill + Agent + Hooks + MCP Server。
常用命令:
/plugin install github@claude-plugins-official # 从官方市场装
/plugin marketplace add anthropics/claude-code # 加第三方市场
/plugin disable plugin-name # 临时禁用
/plugin uninstall plugin-name # 卸载
/reload-plugins # 热加载,无需重启七、Hooks:把「每次都要做」变成「自动做」
Hooks 是 CC 的事件驱动机制——「当 X 发生时,自动跑 Y」。常见用法:
| 事件 | 触发时机 | 典型用途 |
|---|---|---|
| PreToolUse | 工具调用前 | 拦截危险操作 / 自动审批安全命令 |
| PostToolUse | 工具调用后 | 自动 format / lint |
| Notification | CC 发通知时 | 转发到飞书 / Slack |
| Stop | CC 停止响应时 | 保存状态、生成报告 |
| SubAgentStop | SubAgent 完成时 | 子任务通知 |
| SessionStart | 新会话启动时 | 加载上下文、设置环境变量 |
一个最常用的「编辑后自动 prettier」:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{ "type": "command", "command": "npx prettier --write $CC_EDIT_FILE_PATH" }
]
}
]
}
}我自己装得最多的 Hook 是:长任务结束(Stop)→ 推一条飞书机器人消息。再也不用反复回来看屏幕了。
八、Memory:跨会话的持久记忆
CC 的对话默认只活在当前会话。Memory 解决的就是「这次告诉它,下次它还记得」。
存储位置在 ~/.claude/projects/<项目路径>/memory/,按类型分四类:
| 类型 | 用途 | 示例 |
|---|---|---|
| user | 用户画像 | 「用户是后端工程师,熟 Go,正在学 React」 |
| feedback | 工作偏好 | 「偏好简洁回复,不要结尾总结」 |
| project | 项目状态 | 「v2.0 要 3 月 15 前发布,先做支付」 |
| reference | 外部资源 | 「Bug 在 Linear INGEST 项目跟踪」 |
用法很自然——直接说「记住 XXX」或「忘记 XXX」就行。CC 也会在对话中主动识别值得记的信息(比如你纠正了它的某个行为),无需手动触发。
九、上下文管理:决定输出质量的隐藏旋钮
上下文窗口就是 CC 的「工作记忆」。管不好它,能力再强也发挥不出来。
主要消耗源:
| 来源 | 优化策略 |
|---|---|
| 对话历史 | 适时开新会话,用 /compact 压缩 |
| 文件读取 | 指定行号范围,别让 CC 啃整个大文件 |
| 工具输出 | 用 grep / head / tail 管道过滤 |
| CLAUDE.md | 保持精简,避免冗余 |
| Skill 指令 | Skill 本身要短小高效 |
五个实战习惯,按优先级排:
- 一事一议:一个对话聚焦一个任务,任务转向时果断新开
- 善用
/compact:长对话还没干完?让 CC 压缩历史,保留要点 - 精确定位:读文件时给行号或函数名,别整文件灌进来
- SubAgent 分流:信息收集类丢给子 Agent,主窗口只看汇总
- Memory 跨会话:要跨对话用的信息存到 Memory,而不是寄望对话历史
收尾
CC 的强大不在「一个模型」,而在架构本身——Agent 编排、Skill 抽象、MCP 扩展、Hooks 自动化、Memory 持久化几层叠在一起,组合出来的可能性远远超过任何单一 AI 助手。
如果你刚接手 CC,建议按这个顺序走:
- 先把
CLAUDE.md写好(基线) - 把高频工作流封装成 Skill(复用)
- 接入两三个 MCP Server(外援)
- 把重复操作交给 Hooks(自动化)
- 复杂任务才上 SubAgent(并行)
一边用一边补,三个月后再回头看会发现:原来一个人也能像带了一支小队。
💬 留下你的想法~
用 GitHub 账号登录,留个表情或写两句都好——「悄悄告诉你哦,我每条都会看的呢」